Predicting Flight Arrival Delays: Machine Learning Approaches
Midterm Report
Introduction
Air travel, renowned for its speed and global connectivity, remains vulnerable to unforeseen disruptions. Despite the high level of operational planning in the aviation industry, where flight schedules are often determined months in advance, unpredictable variables such as weather, air traffic congestion, and technical issues continue to cause significant delays [1]. These disruptions have wide-ranging economic, environmental, and social impacts. In 2019 alone, flight delays were estimated to cost the U.S. economy approximately $33 billion, encompassing direct airline costs, fuel wastage, crew rescheduling, and indirect effects on connected industries such as hospitality and tourism [8].
Related Work
The prediction of flight delays has attracted research due to its economic, operational, and environmental implications. Traditional statistical models were initially employed to analyze delay causes, however, their limited ability to capture nonlinear interactions between operational, temporal, and meteorological variables has motivated the adoption of machine learning (ML) techniques.
Hatipoğlu and Tosun [1] investigated flight delay prediction at a Turkish airport using multiple ML classifiers, including Logistic Regression, Naïve Bayes, Neural Networks, Random Forest, XGBoost, CatBoost, and LightGBM. Their results demonstrated that ensemble-based approaches, particularly XGBoost, achieved superior predictive performance, reaching an accuracy of 80%. The study also addressed class imbalance using the Synthetic Minority Over-Sampling Technique (SMOTE) and applied SHAP (SHapley Additive exPlanations) for model interpretability, revealing the relative contribution of operational and weather-related features.
Similarly, Meel et al. [3] and R. G. et al. [9] evaluated multiple ML classifiers such as Logistic Regression, Decision Trees, Bayesian Ridge, Random Forest, Gradient Boosting, and Support Vector Machines for flight delay prediction. Their results confirmed that tree ensemble models and kernel methods outperform simpler regression baselines by effectively capturing complex dependencies in flight operations, weather, and air traffic congestion. The model proposed by R. G. et al. [9] achieved an accuracy of 95%, highlighting the scalability of ML-driven approaches when trained on large, heterogeneous datasets.
Li et al. [4] extended this line of research using data from the U.S. Bureau of Transportation Statistics (BTS) to compare several ML and computational intelligence methods, including linear regression, random forest, gradient boosting, Gaussian regression, and genetic programming, for predicting arrival delay time. Their findings indicated that genetic programming provided the best predictive accuracy, emphasizing the benefit of evolutionary optimization methods in modeling aviation delays.
Finally, Huynh et al. [5] conducted a systematic review of flight delay forecasting models, concluding that Artificial Neural Networks (ANNs) and Random Forests are the most robust and widely used frameworks. The review further emphasized the importance of feature selection, identifying flight attributes, meteorological conditions, and temporal factors as critical inputs that significantly influence model performance.
Collectively, prior studies demonstrate that machine learning offers a powerful framework for delay prediction by integrating operational, temporal, and environmental variables. However, most existing works are either restricted to specific regions or employ older datasets. Moreover, while ensemble methods and neural networks consistently deliver high predictive accuracy, model generalization across airports and varying traffic conditions remains an open challenge. This motivates our study, which focuses on developing and evaluating ML-based classifiers to predict arrival delays at Hartsfield–Jackson Atlanta International Airport (ATL) using recent BTS data spanning 2019–2025, thereby contributing a large-scale and region-specific analysis to the growing body of literature on flight delay forecasting.
Dataset
For this project, we use flight performance data from the U.S. Bureau of Transportation Statistics (BTS),
specifically arrivals at Hartsfield–Jackson Atlanta International Airport (ATL) from 11 different airlines.
The dataset covers domestic flights over the past five years (2019-2025, excluding 2020 and 2021 due to COVID-19 disruptions).
It contains detailed records such as scheduled and actual times, delay, cause of delay, etc.
Dataset link: BTS On-Time Arrival Data [6].
Problem Definition
According to the Bureau of Transportation Statistics (BTS), in 2024 there were 787,630 arrival delays across the United States [7], underscoring the scope and recurrence of this issue. Machine learning has been used for several years as a tool to address this issue, and it has been proven to be a powerful and effective one. To standardize our analysis, we adopt the Federal Aviation Administration (FAA) definition of a delay, which considers a flight delayed if its arrival time is more than 15 minutes later than scheduled. This definition provides a consistent framework for modeling and evaluating flight delays.
In this project, we formulate the prediction task primarily as a binary classification problem, where the goal is to determine whether a flight will arrive on time or delayed based on pre-departure features. Additionally, we plan to explore a regression formulation that predicts the expected delay duration (in minutes) for flights identified as delayed. Together, these complementary approaches enable both categorical delay detection and quantitative delay estimation, offering a more comprehensive view of flight delay behavior and potential mitigation strategies.
Methods
For our project on predicting flight delays, we will use a mix of preprocessing steps and supervised machine learning models. The goal is to clean and prepare the data so that our models can make reliable predictions.
Data Preprocessing
Before implementing the model, we implemented an extensive preprocessing pipeline to ensure the data remained consistent and reliable for all models.
The preprocessing procedures was executed in the notebooks 01_exploratory_data_analysis.ipynb, 02_data_preprocessing.ipynb, 03_feature_engineering.ipynb
with the help of scripts under the directory src/data/.
Exploratory Data Analysis
The dataset from the Bureau of Transportation Statistics (BTS)
[6] includes flights from
11 major U.S. airlines spanning 2019–2025 (until July 31).
Separate .csv files for each carrier and year were merged into a unified dataset (.csv File).
While doing exploratory data analysis (EDA), we analysed the distributions of the features and also summary of the statistics of the features.
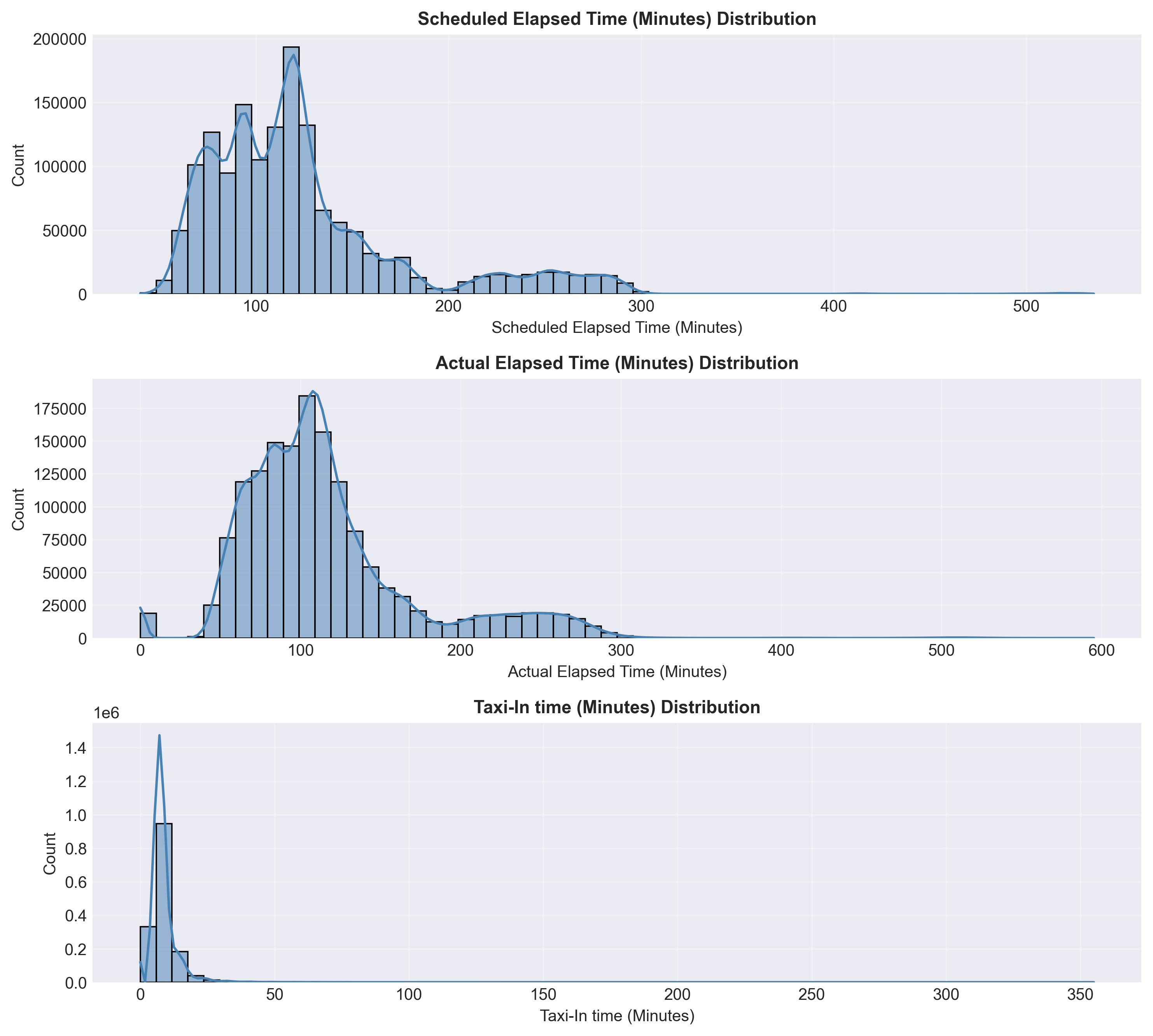
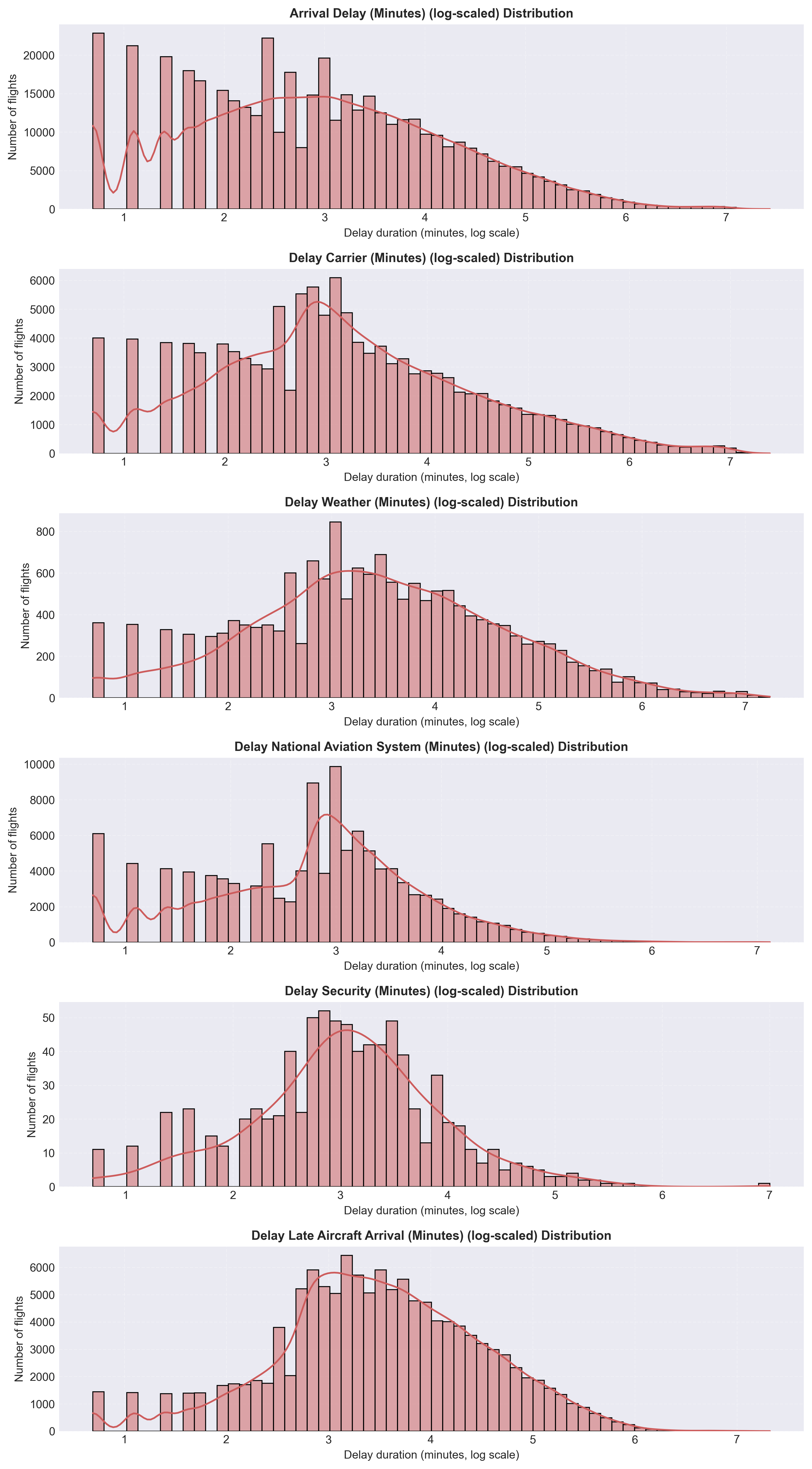
It can be seen in Figure 1a and Figure 1b that expected flight durations were 60–200 minutes and there were highly right-skewed delay variables.
Most flights arrived on time, while a small subset experienced long carrier- or aircraft-related delays.
These insights guided data cleaning, outlier handling, and the creation of the binary label (Delay or Not Delayed).
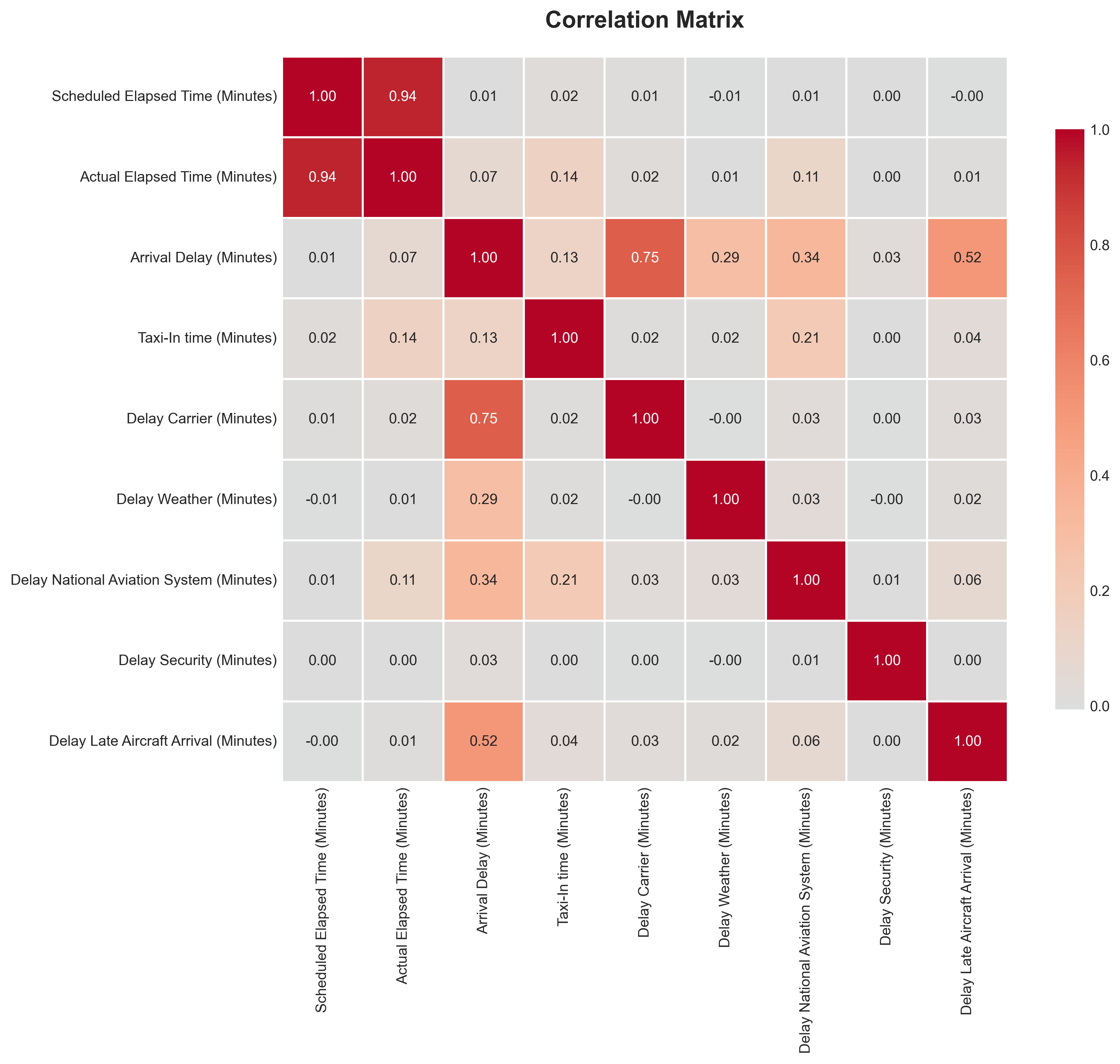
The correlation matrix (Figure 2) shows strong relationships between Scheduled and Actual Elapsed Times (r ≈ 0.94), confirming internal data consistency. Arrival Delay correlates most strongly with Carrier Delay (r ≈ 0.75) and Late Aircraft Arrival (r ≈ 0.52), indicating that operational and turnaround factors are the primary drivers of delay propagation. Other causes such as Weather and Security exhibit weaker correlations, reflecting their infrequent nature.
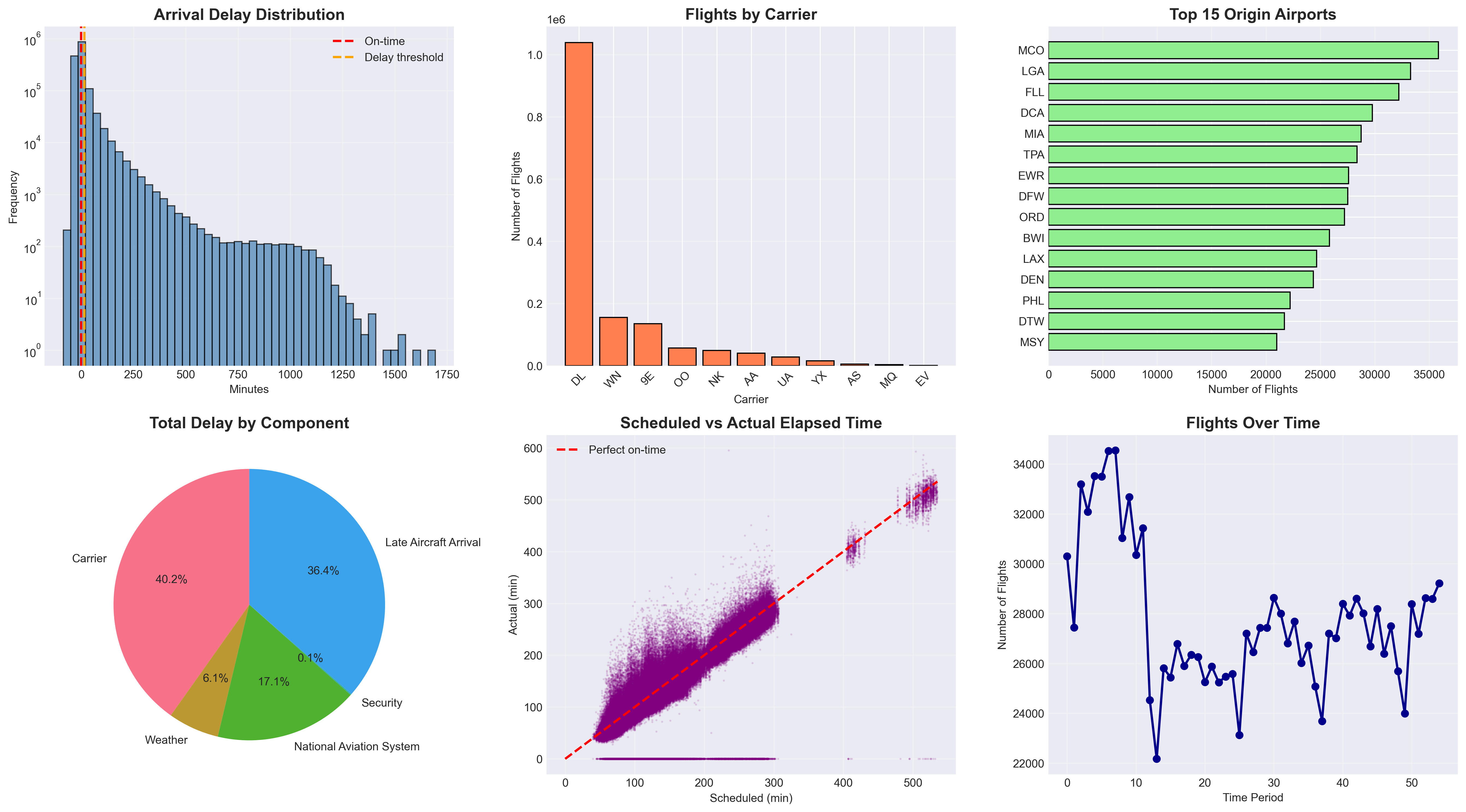
Overall, EDA confirmed the dataset’s consistency and revealed that delay patterns are primarily caused by carrier and aircraft factors. These findings provided the foundation for next steps.
Data Cleaning and Transformation
After data integration, a systematic preprocessing pipeline was applied to ensure data quality and consistency.
Invalid rows were removed, data types were standardized, and categorical variables were converted to appropriate formats.
Invalid rows with missing critical information such as flight times or delay components were removed to ensure record completeness.
Data types were standardized by converting date fields to datetime format, ensuring numerical columns (e.g., elapsed and delay times)
used consistent integer types, and coercing non-numeric values to NaN where necessary.
Categorical variables, including Carrier Code and Origin Airport, were converted to efficient
category types to improve memory usage and facilitate encoding during modeling.
Missing numeric values were imputed using the median, while categorical gaps such as Tail Number were filled with Unknown.
Outliers were reviewed but retained to preserve the natural variability of flight operations, as the selected models are robust to such values.
Duplicates were eliminated, and date fields were normalized to the canonical format Date (YYYY-MM-DD).
Figure 3 summarizes the dataset after preprocessing. The cleaned data exhibit consistent structure and realistic operational patterns: most flights last between 60–200 minutes, carrier-related delays dominate total delay composition, and the strong correspondence between scheduled and actual elapsed times confirms internal data reliability.
Feature Engineering
Building on the cleaned dataset, new features were engineered to capture temporal, categorical, and operational factors influencing flight delays.
Binary indicators such as IsWeekend and Is_Holiday_Period were derived from flight dates to represent temporal travel patterns,
while Season was encoded into four categories (Fall, Spring, Summer, Winter) to capture seasonal variation.
The target variable Is_Delayed was defined according to the FAA’s 15-minute threshold.
Categorical variables were transformed for modeling: Carrier Code was one-hot encoded,
Origin Airport was label-encoded, and Season was numerically encoded for model compatibility.
The final engineered dataset included 16 predictive features spanning operational, temporal, and categorical dimensions:
- Operational:
Scheduled Elapsed Time (Minutes),IsWeekend,Is_Holiday_Period - Carrier-specific dummies (11):
Carrier_9E,Carrier_AA,Carrier_AS,Carrier_DL,Carrier_EV,Carrier_MQ,Carrier_NK,Carrier_OO,Carrier_UA,Carrier_WN,Carrier_YX - Encoded categorical:
Origin_Airport_Encoded,Season_Encoded
Figure 4 visualizes these engineered features and their relationships. Delays tend to be slightly higher during weekends and summer months, while carrier-level patterns highlight differences in operational performance. Together, these features provide a compact yet comprehensive representation of factors relevant to flight delay prediction.
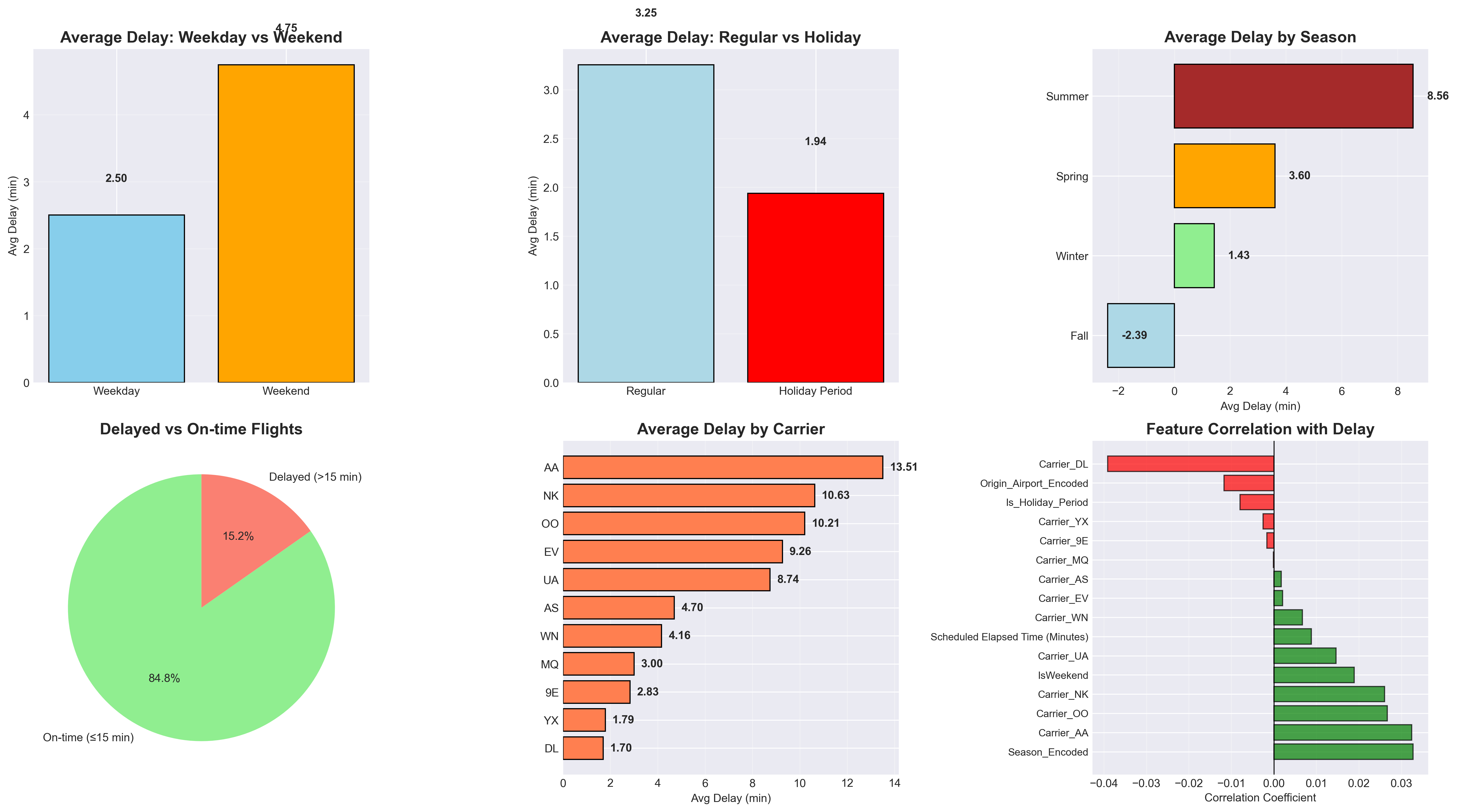
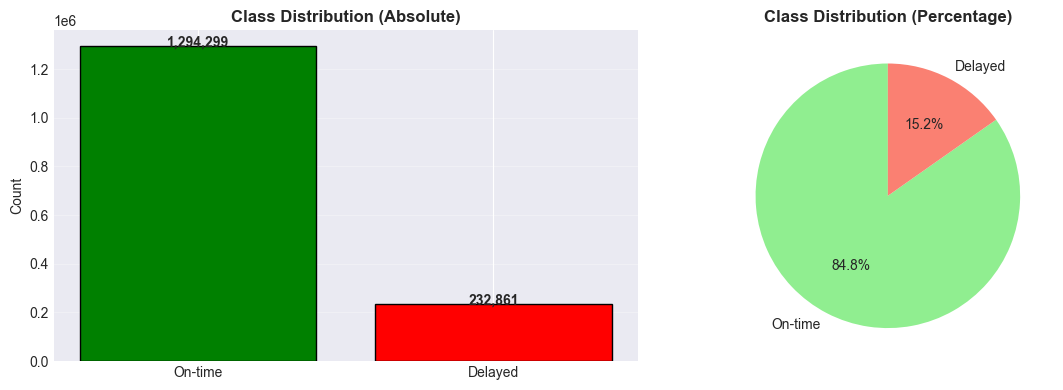
Class Distribution
The class distribution shown in Figure 5 reveals a significant imbalance: approximately 84.8 % of flights arrived on time, while only 15.2 % were delayed. This skew can bias models toward predicting the majority “on-time” class, resulting in poor sensitivity to delay events. To address this, we evaluated both imbalanced (default) and balanced model variants in subsequent experiments. As discussed in class, ensemble methods such as Random Forests often perform reasonably well even under class imbalance, but applying explicit class weighting can further improve the detection of minority-class instances.
Machine Learning Models
Logistic Regression
We adopted a phased project strategy, beginning binary classification before advancing to regression.
This allows us to tackle a simpler task and evaluate the initial model's performance to validate the quality of our dataset and our data preprocessing techniques before investing time in more complex regression models.
Logistic Regression, which was the first supervised learning algorithm introduced in class, was selected as our first (baseline) model due to its simplicity, computational speed, and also interpretability. The algorithm estimates the probability that a given instance belongs to the “delayed” class. As a linear classifier, it provides coefficients that quantify the influence of each feature on the likelihood of a flight delay. This property not only facilitates a transparent understanding of model behavior but also allows domain experts, such as airline and airport operations personnel, to validate the model’s reasoning and potentially integrate its predictions into operational decision-making processes. Therefore, this model could have a direct real-world impact in optimizing air traffic logistics.
We performed 3-Fold Cross-Validation, meaning the dataset was divided into three equally sized folds while preserving the class distribution in each split. In each iteration, it is trained on two folds and validated on the remaining one. This enables us to select the best value for the regularization hyperparameter λ (lambda), which mitigates the risk of overfitting to any subset of the data. We are currently using 0.5 as the probability threshold for classification.
Random Forest
After establishing the baseline with Logistic Regression, we implemented a Random Forest Classifier to capture nonlinear dependencies that a linear model cannot represent. Random Forests are ensemble methods that construct multiple decision trees on random subsets of data and features, then aggregate their outputs through majority voting and it was mentioned in the lecture, that ensemble methods handle imbalanced data well.
We began by training a baseline Random Forest using default parameters, followed by two improved variants:
a balanced model addressing class imbalance via class_weight='balanced',
and a tuned model optimized using RandomizedSearchCV
with F1-score as the objective metric.
The tuning process explored the number of estimators, tree depth, and minimum sample thresholds
(n_estimators from [100, 200, 300];
max_depth from [10, 20, 30, None];
min_samples_split from [2, 5, 10, 20];
min_samples_leaf from [1, 2, 4, 10]).
Three-fold cross-validation was used to ensure stable generalization across data splits, similarly to the approach used in logistic regression.
The Random Forest algorithm was selected because of its ability to model complex relationships, handle mixed feature types, and remain robust to outliers and noise. Unlike linear models, it can naturally capture interactions between operational and temporal variables, such as how flight duration, departure airport, and seasonal patterns jointly influence delay probability. Additionally, its feature importance output provides interpretability by quantifying each variable’s contribution to the prediction, making it suitable for both predictive and diagnostic insights. The results will be discussed in the next section.
The resulting tuned model demonstrated an improved balance between recall and precision compared to the baseline, indicating its effectiveness in identifying delayed flights while limiting false positives. This makes Random Forest a practical choice for early delay detection systems where minimizing missed delay alerts is more critical than achieving perfect precision.
Results and Discussion
To better understand model performance, we analyzed the confusion matrices for both the unbalanced and balanced logistic regression and random forest models.
Logistic Regression
The unbalanced model predicted almost all flights as “not delayed,” resulting in a confusion matrix heavily skewed toward the majority class. The balanced model showed a more reasonable distribution of predictions, correctly identifying a portion of the delayed flights, although it also misclassified a significant number of non-delayed flights as delayed.
These visualizations highlight the impact of class imbalance and the importance of accounting for it when modeling delay prediction problems.
Visualizations
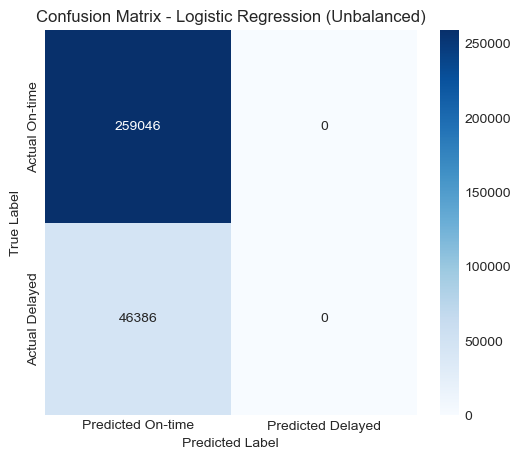
Confusion Matrix — Unbalanced
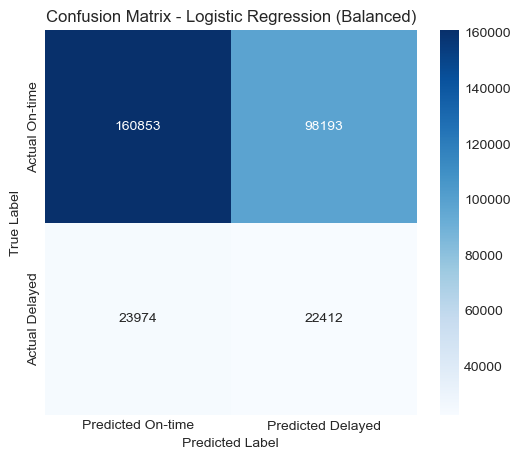
Confusion Matrix — Balanced
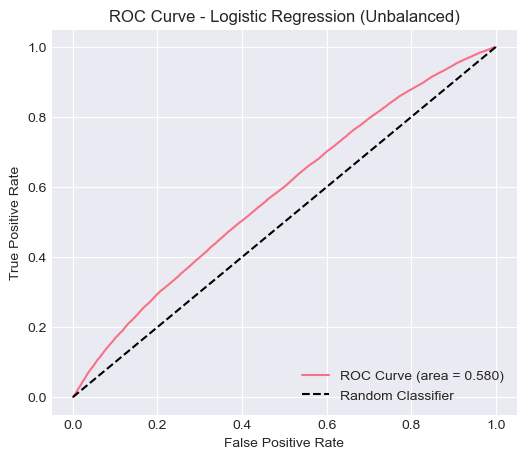
ROC Curve — Unbalanced
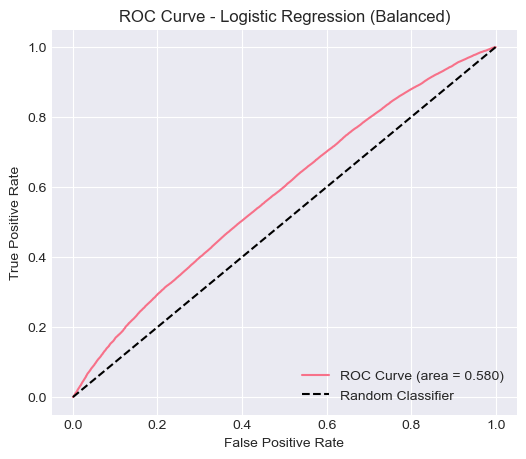
ROC Curve — Balanced
Quantitative Metrics
| Model | Accuracy | Precision | Recall | F1-Score | ROC-AUC |
|---|---|---|---|---|---|
| Logistic Regression (Unbalanced) | 0.8481 | 0.0000 | 0.0000 | 0.0000 | 0.5805 |
| Logistic Regression (Balanced) | 0.6000 | 0.1858 | 0.4832 | 0.2684 | 0.5805 |
The unbalanced model achieved high accuracy (0.8481) but failed to identify any delayed flights (recall = 0), indicating that it learned to always predict the majority class. This is a common issue in imbalanced datasets, where accuracy can be misleading because predicting the dominant class yields superficially strong results.
When class weights were balanced, the model’s recall improved to 0.4832, and F1-score increased to 0.2684, showing that the model was able to capture more delayed flights, albeit with lower overall accuracy. The ROC-AUC (0.5805) remained roughly the same in both cases, suggesting that the model’s overall discriminative ability between delayed and non-delayed flights remains limited.
Analysis of the Logistic Regression Model
The logistic regression model serves as a strong baseline for this classification problem. Its interpretability and computational efficiency make it suitable for early-stage analysis. However, the results indicate that the model struggles with the class imbalance inherent in the dataset, where only 15% of flights are delayed.
In the unbalanced case, the model simply defaulted to predicting the majority class (no delay), leading to poor performance on minority cases. Applying balanced class weights improved detection of delayed flights, but the model still lacked predictive strength. This suggests that the linear decision boundary of logistic regression may not adequately capture the complex, nonlinear patterns associated with flight delays (e.g., interactions between weather, airport congestion, and time of day).
Feature Importance Analysis
The logistic regression model also allows us to interpret which variables most strongly influence flight delay predictions.
The top 15 most influential features (by absolute coefficient value) indicate that seasonality (Season_Encoded) has the strongest positive association with delays, suggesting that certain times of the year (e.g., winter or summer travel peaks) are more prone to delays.
Several airline carrier indicators (e.g., Carrier_DL, Carrier_NK, Carrier_AA) also show substantial influence, reflecting performance differences among airlines.
Operational features such as Scheduled Elapsed Time (Minutes) and IsWeekend further contribute, implying that longer scheduled flights and weekend departures have a higher likelihood of delay.
In contrast, some features like Origin_Airport_Encoded or Is_Holiday_Period show negative or weaker coefficients, indicating they are less predictive or associated with fewer delays in this dataset.
Overall, this analysis highlights that both temporal factors (season, weekend) and carrier-specific effects play a key role in determining whether a flight is delayed.
Random Forest
The Random Forest classifier was trained under two configurations, the original (imbalanced), and tuned model (balanced). The confusion matrices and ROC curves below compare the model’s ability to correctly identify delayed flights before and after applying class weighting and hyperparameter tuning. The tuned model shows improved recall, and F1-score for the delayed class while maintaining a similar overall ROC–AUC, indicating better sensitivity to minority cases without overfitting.
Visualizations

Confusion Matrix — Original

Confusion Matrix — Balanced (Tuned)

ROC Curve — Original

ROC Curve — Balanced (Tuned)
Quantitative Metrics
| Model | Accuracy | Precision | Recall | F1-Score | ROC-AUC |
|---|---|---|---|---|---|
| Random Forest (Original) | 0.8480 | 0.4623 | 0.0071 | 0.0141 | 0.6386 |
| Random Forest (Balanced) | 0.6326 | 0.2184 | 0.5502 | 0.3126 | 0.6367 |
Quantitatively, the balanced model improved recall (approximately 0.55) compared to the original model’s near-zero recall (0.007), confirming that class weighting allowed the model to recognize more delay cases. While overall accuracy decreased (0.63 from 0.85), this trade-off is expected and desirable for imbalanced data. The ROC–AUC remained stable at around 0.64, suggesting the model's ability to discriminate between on-time and delayed flights improved in balance rather than separability.
Analysis of Random Forest
The tuned Random Forest used n_estimators = 200, max_depth = 20,
min_samples_split = 20, min_samples_leaf = 4, and
class_weight = 'balanced'. This configuration achieved the highest F1-score (≈0.31)
and a stable ROC–AUC (≈0.64). Feature importance analysis revealed that
Scheduled Elapsed Time, Origin Airport, and Season were the most influential predictors,
together accounting for over 80% of the model’s decision weight.
This indicates that both operational and temporal factors strongly shape delay likelihood, while
individual carriers contribute comparatively less.

Top 15 Feature Importances — Random Forest model highlighting operational and temporal predictors.
Overall, the Random Forest model demonstrates robustness to noise and outliers and benefits from class weighting to improve minority detection. Its moderate discriminative power suggests that further improvement may depend on integrating external variables such as weather, air traffic congestion, and time-of-day effects to capture real-world variability in flight delays.
Next Steps
The current Random Forest classifier achieved moderate performance, indicating that while the model captures some key operational patterns, additional features and modeling strategies are required to improve prediction accuracy. Based on these findings, the next steps are as follows:
- Incorporate Weather Data: Integrate external meteorological variables (e.g., temperature, wind speed, precipitation) from the NOAA to better represent environmental conditions influencing flight delays. Although current accuracy is decent, prior research [1-5] on flight delay prediction demonstrates that weather-related features can improve model performance, making this a logical extension of our current work.
- Extend to Regression Modeling: Move beyond binary classification to a regression framework that predicts the actual delay duration (in minutes). This would allow a more fine-grained understanding of delay severity and support more practical scheduling insights.
- Explore Advanced and Ensemble Models: Evaluate neural network architectures such as Multilayer Perceptrons (MLPs) and ensemble methods (e.g., XGBoost, LightGBM) to capture nonlinear interactions between temporal, carrier, and airport-level factors.
References
[1] I. Hatipoğlu and Ö Tosun, “Predictive modeling of flight delays at an airport using machine learning methods,” Applied Sciences, vol. 14, no. 13, p. 5472, 2024.
[2] N. Kuhn and N. Jamadagni, Application of machine learning algorithms to predict flight arrival delays. Course Project Report CS229, Stanford University, 2024. [Online]. Available: https://cs229.stanford.edu/proj2017/final-reports/5243248.pdf
[3] P. Meel, M. Singhal, M. Tanwar and N. Saini, "Predicting flight delays with error calculation using machine learned classifiers," 7th International Conference on Signal Processing and Integrated Networks (SPIN)*, 2020, pp. 71-76.
[4] J. Li et al., "Prediction of flight arrival delay time using U.S. Bureau of Transportation Statistics," 2023 IEEE Symposium Series on Computational Intelligence (SSCI), Mexico, 2 023, pp. 603-608.
[5] T. K. Huynh, T. Cheung and C. Chua, "A systematic review of flight delay forecasting models," 2024 7th International Conference on Green Technology and Sustainable Development (GTSD), 2024, pp. 533-540.
[6] Bureau of Transportation Statistics, U.S. Department of Transportation, 2025. “On-Time Performance Data (Arrivals),” distributed by Bureau of Transportation Statistics. Available: https://www.transtats.bts.gov/ONTIME/Arrivals.aspx
[7] Bureau of Transportation Statistics, U.S. Department of Transportation, 2024. “Number of Delayed Flights in 2024,” distributed by Bureau of Transportation Statistics. Available: https://www.transtats.bts.gov/Marketing_Annual.aspx?heY_fryrp6lrn4=FDFI&heY_fryrp6Z106u=J&heY_gvzr=E&heY_fryrp6v10=E
[8] Federal Aviation Administration, 2020, "Cost of Delay Estimates," distributed by Federal Aviation Administration (FAA).
[9] R. G, K. Vijaya, S. Sadesh, A. P. M, M. P. V and M. S. Kumar, "Predicting Flight Delays and Error Calculation Using Machine Learning Classifiers," 5th International Conference on Electronics and Sustainable Communication Systems (ICESC), India, 2024, pp. 1238-1244.